I will try to be brief.
## Large table MacOS test
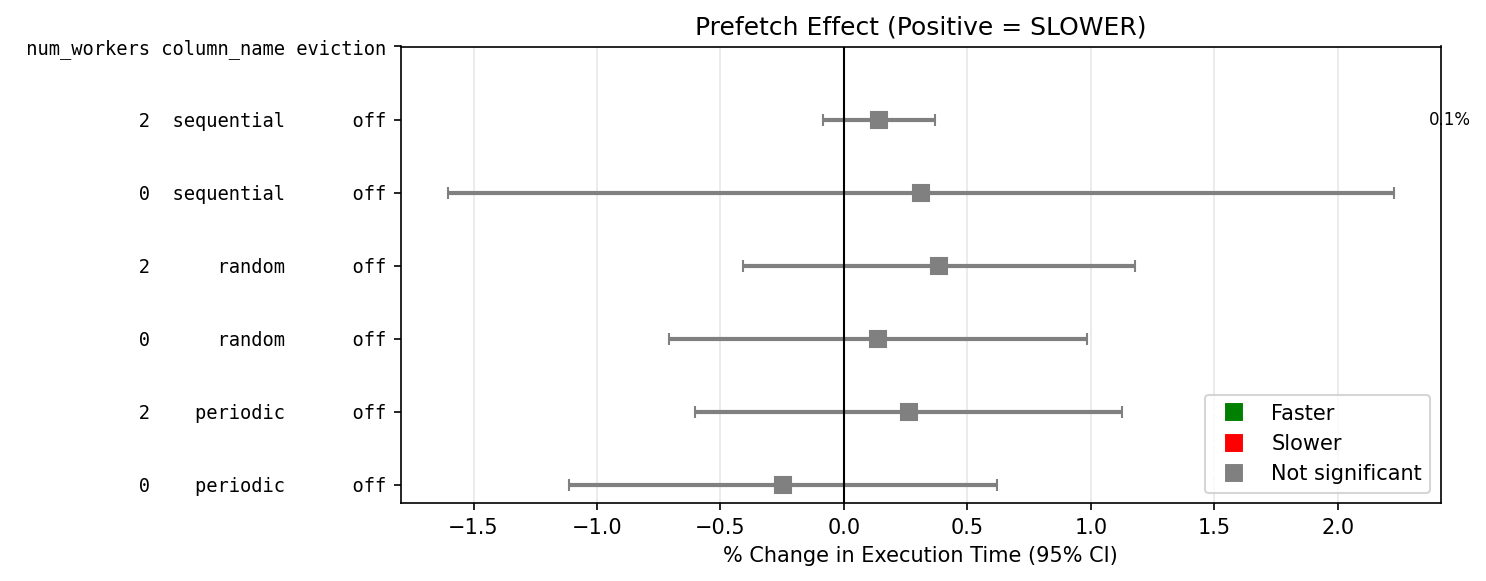
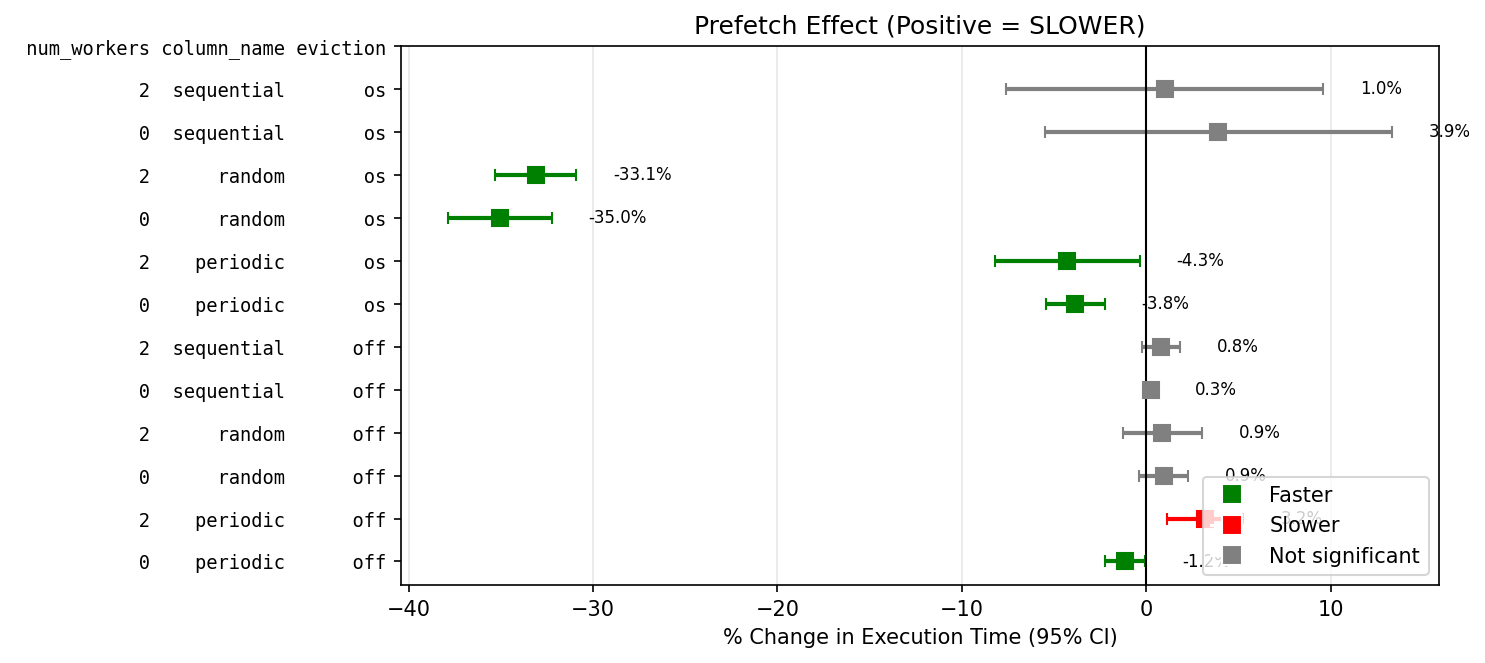
I did a 1000x larger test in MacOS, with the sql script . prefetch had negligible effect for random and periodic, and made sequential 16% slower [a].
## Small scale linux test.
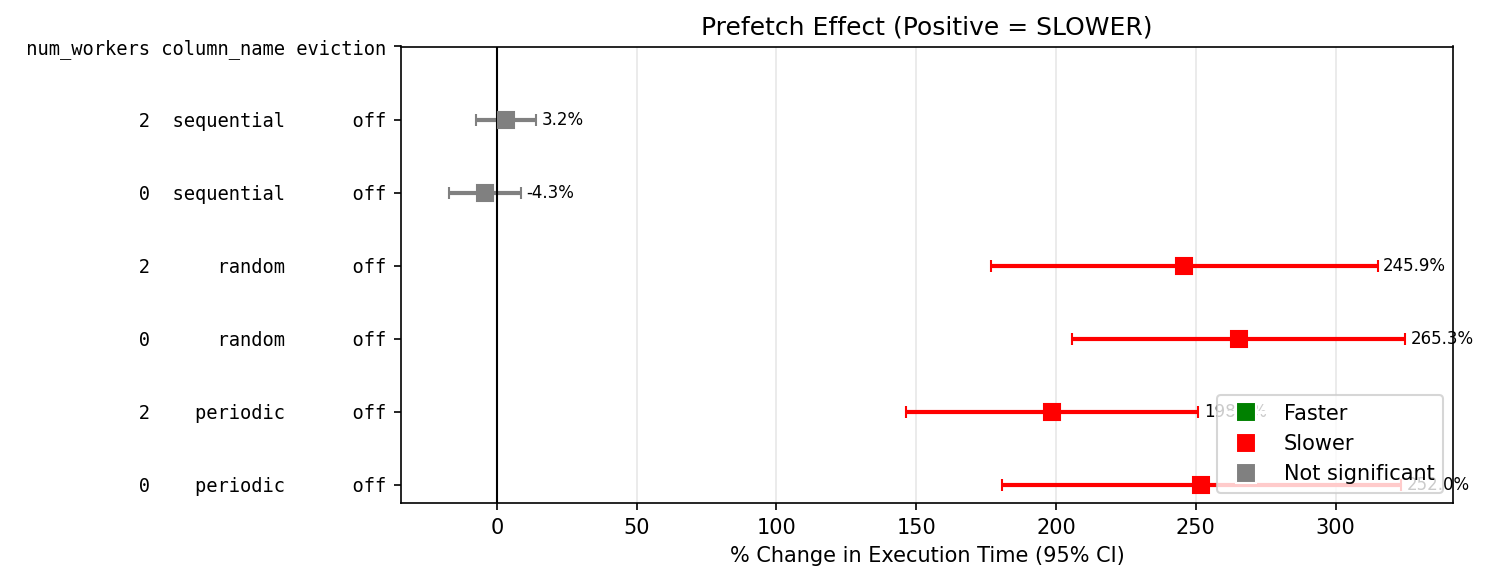
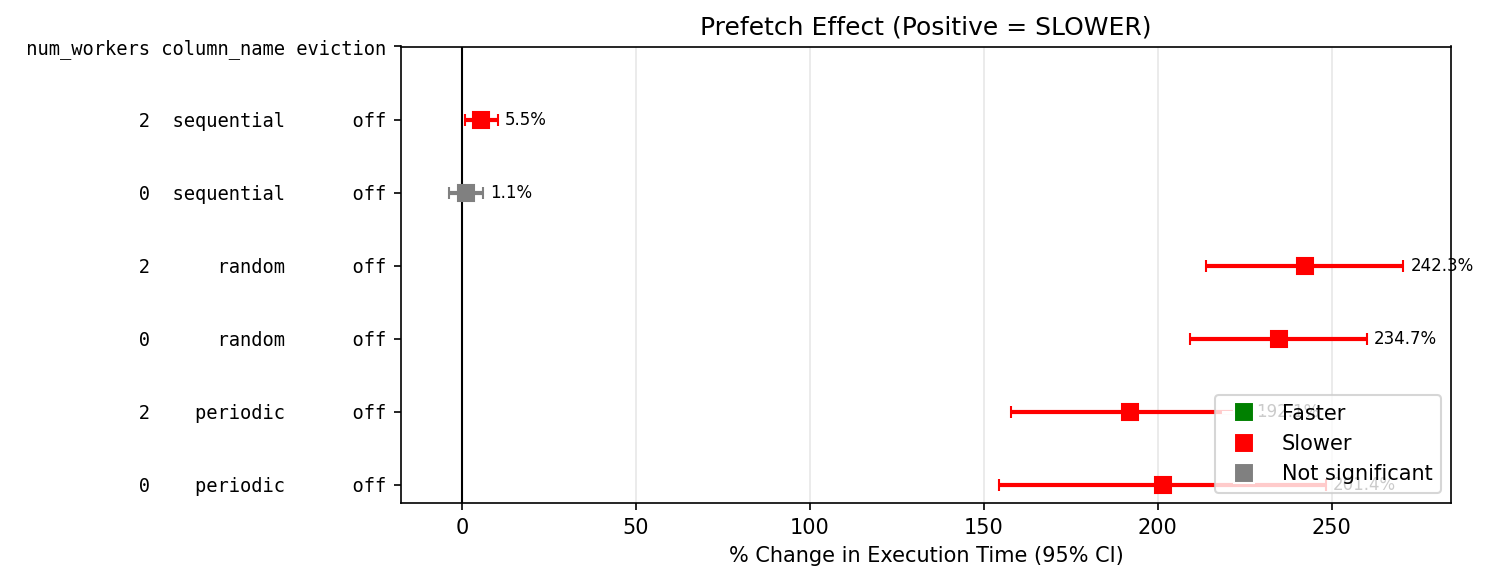
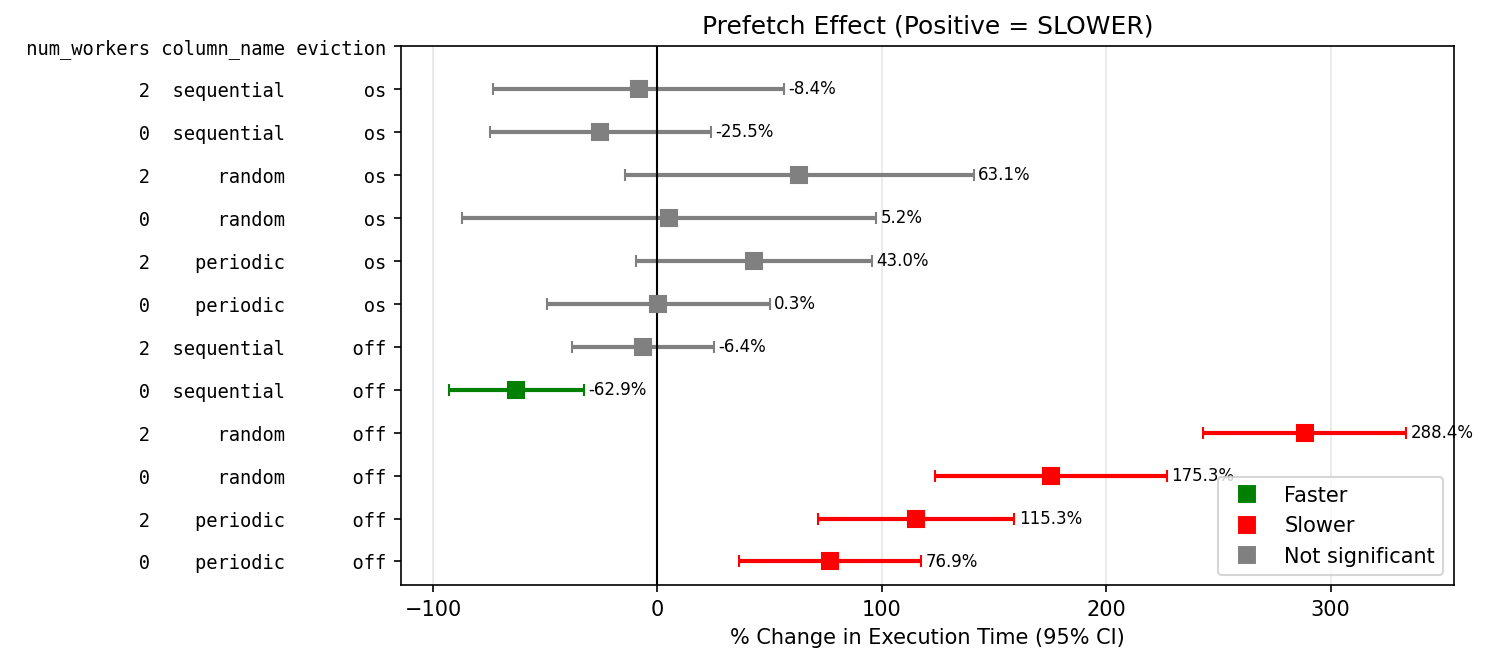
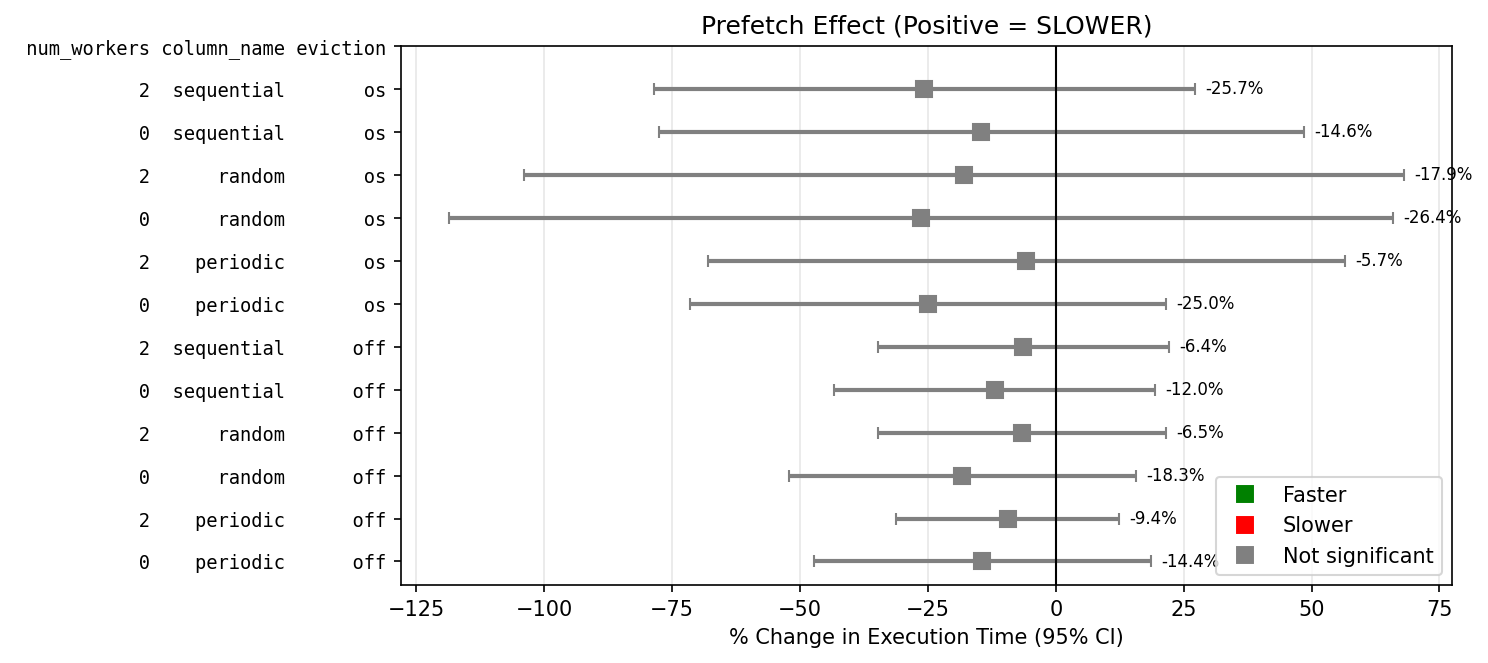
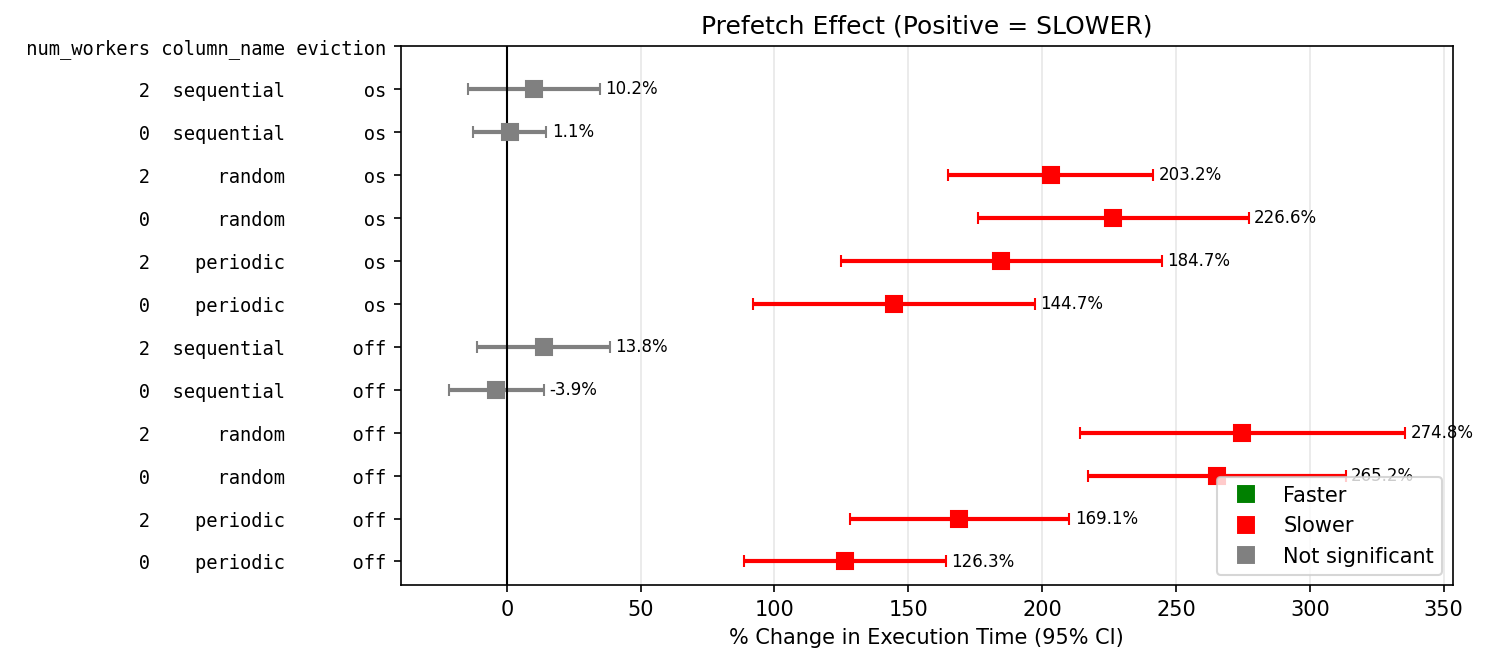
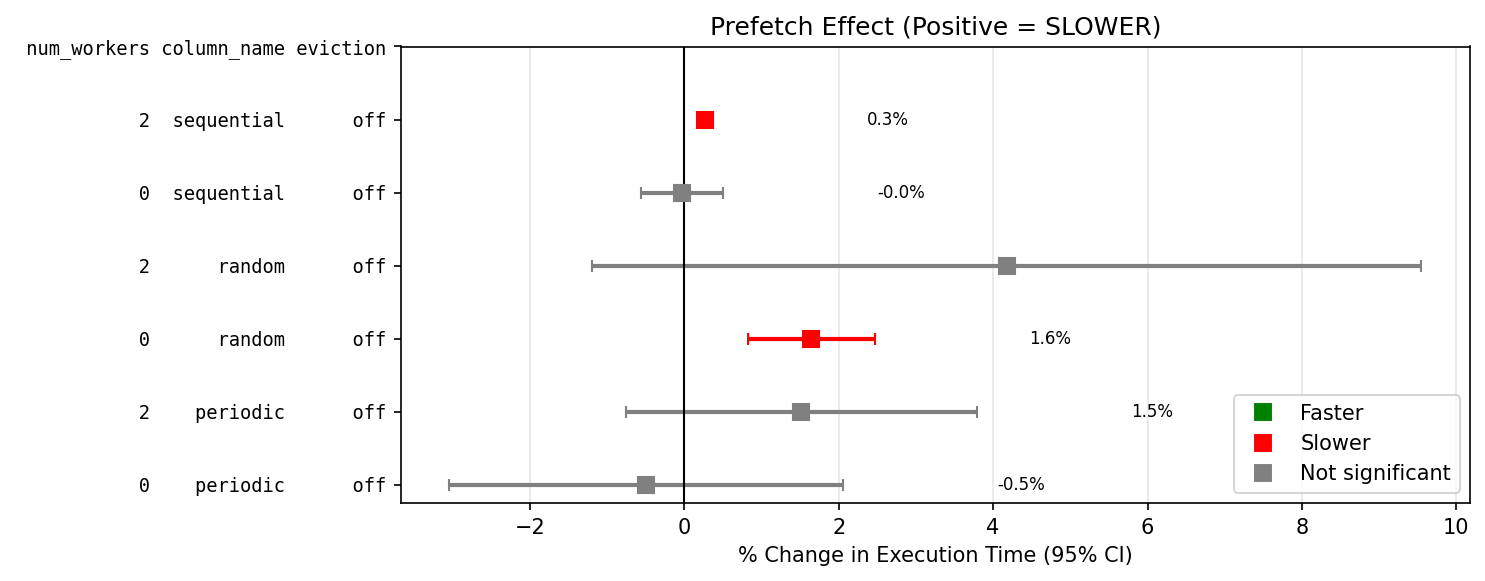
I have repeated the tests with a 10k table row on a linux system, this time I tried using either a SSD or a HDD, with shared_buffers of either 128kB or 128MB, and either psql or python with psycopg. I used a slightly different table [b].
Prefetch makes...
SDD with low available buffers is significantly slower, except for sequential reads.
SDD with cold OS reads is significantly faster for random access.
HDD faster, but not reliably (high variance).
I am not questioning the usefulness of the patch, and I know that there is a log of work already put into it. The reason why I decided to review it is because I believe this can be one important step forward. But I hope that it is not hard to agree that these (counter)examples suggest that there are some edges to be pruned. Where I work, most of the queries will access at most a few hundred lines and are expected to be perceived as instantaneous.
If the tests I am doing are pointless, should we consider having something in the planner to prevent these scans from using prefetch?
Should we introduce centralized coordination for IO? As far as I know this is an area where we just let each query request what they need and hope for the best. What happens if we have two sequential scans in different tables? the disk access could interleave pages of the two scans, falling into a random access pattern, right?
### Cache control
This is a way to make the script run without sudo in linux, you give ownership to root, and then you pin this program to the owner
% gcc drop_cache.c -o drop_cache;
% sudo chown root:root drop_cache;
% sudo chmod 4755 drop_cache;
In MacOS purge in the sudoers[2] temporarily, similar to [3]
user ALL=(ALL) NOPASSWD: /usr/bin/purge
So that I don't need to give sudo privileges to the script (that imports code that I am not even aware of).
Notes:
[a] I did some profiling with sample [4], and tried to spot functions with the highest increase or decrease in run time, but I was too confused, no point in dumping raw logs here.
[b] This time I used a (SELECT string_agg((i*j)::text, '+') FROM generate_series(1, 50)) instead of repeat('x', 100), just to prevent it from compressing to nothing when I try larger payloads, and hit the TOAST thresholds. I removed the primary key `id` because it was annoying to take 20 minutes to insert the data in the large scale test.
References:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}