Selective tuple deformation - Mailing list pgsql-hackers
| From | David Rowley |
|---|---|
| Subject | Selective tuple deformation |
| Date | |
| Msg-id | CAApHDvpRT3pMUPznqq2MtM6iNo86KFN-bQTkb7H1yC2gLKbWpA@mail.gmail.com Whole thread |
| List | pgsql-hackers |
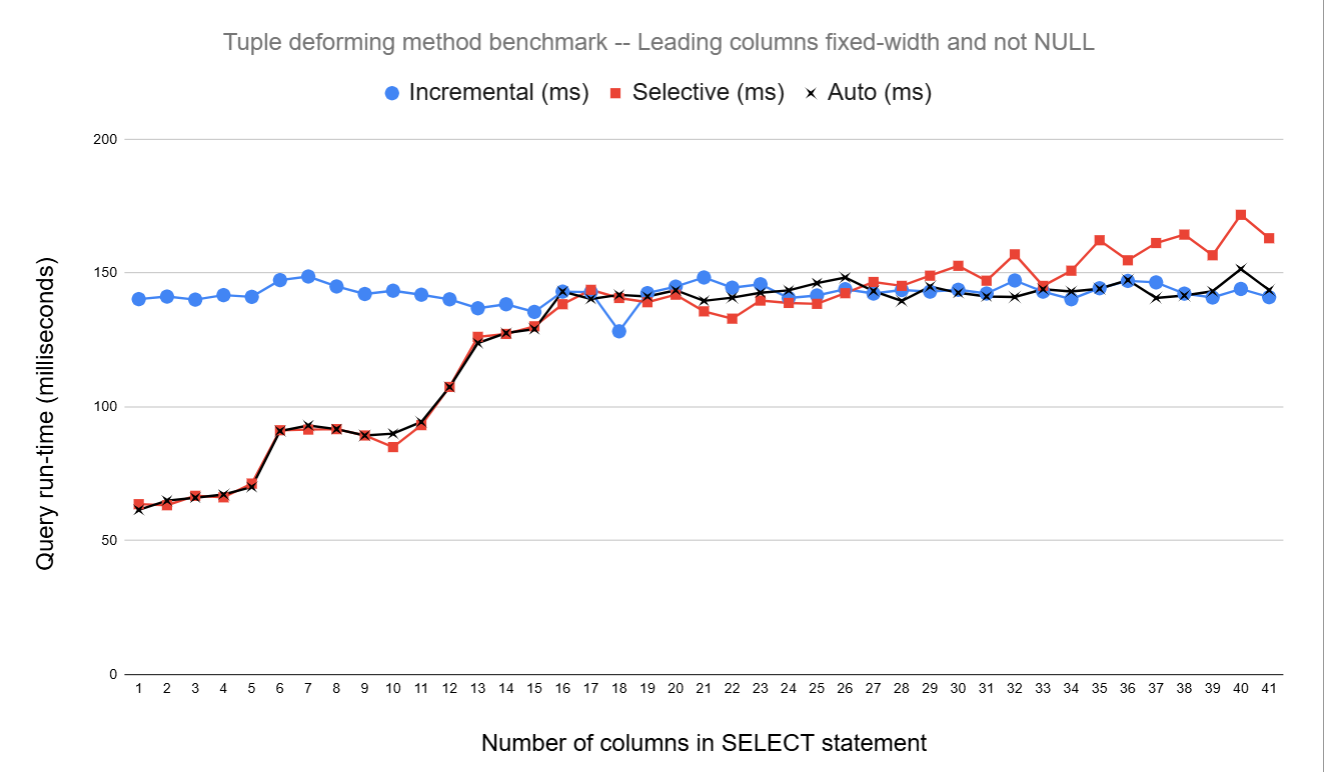
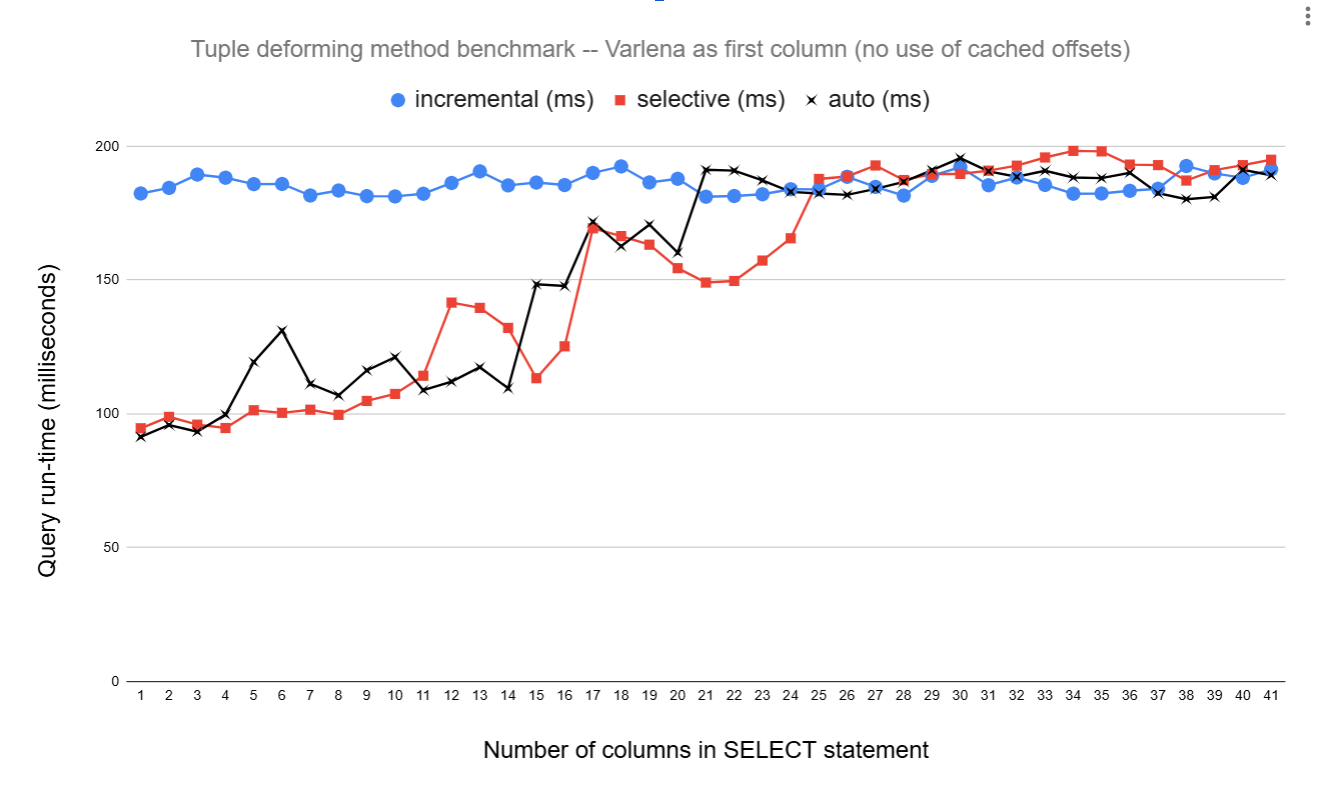
(v20 material) Last month, in [1], I mentioned that I was working on more tuple deforming speedups. This time it's "selective" tuple deforming. Let me explain... As of today, if we need, say, column 10 in a table and nothing else, we deform columns 1-10. This is wasteful. Since c456e3911, CompactAttribute.attcacheoff is always populated, so in many cases, we know the byte offset where the required attribute's value is stored within the tuple. When we know this, it makes sense to only deform the attributes that we need for the query, rather than all attributes up and including the one we need. What we can't really do is just change the deforming code to always selectively deform the tuple. There are some extra overheads to tracking which columns we need, so for queries that require all attributes from a table, we save nothing and only add additional overhead for the attribute tracking. To get around this issue, I've made it so we support both the existing method and this new selective method, this has been added via a new operator named EEOP_SCAN_SELECTSOME. The deformer that's used is selected based on which attributes and how many attributes are being selected. In theory, there should be some heuristic that we can come up with that picks the best one for the job. Let's say we have a table with 41 INT NOT NULL columns, and we only want the 41st column. A query like SELECT col41 FROM t WHERE col41=0; where t contains 1 million rows, none with col41=0, currently profiles as: 66.72% postgres [.] tts_buffer_heap_getsomeattrs <--- 9.73% postgres [.] ExecInterpExpr 3.87% postgres [.] heap_prepare_pagescan 2.96% postgres [.] ExecSeqScanWithQualProject 2.82% postgres [.] heapgettup_pagemode 1.84% postgres [.] ExecStoreBufferHeapTuple 1.45% postgres [.] hash_bytes 1.26% postgres [.] heap_getnextslot Tuple deformation is taking over 66% of the query time. If we swap to selective deforming, this goes to: 21.32% postgres [.] heapgettup_pagemode 12.71% postgres [.] ExecInterpExpr 11.31% postgres [.] heap_prepare_pagescan 8.76% postgres [.] ExecStoreBufferHeapTuple 8.54% postgres [.] heap_getnextslot 7.15% postgres [.] ExecSeqScanWithQualProject 6.83% postgres [.] tts_buffer_heap_selectattrs <--- 2.45% postgres [.] hash_bytes 1.66% postgres [.] LWLockRelease 1.16% postgres [.] hash_search_with_hash_value 1.06% postgres [.] ReservePrivateRefCountEntry The new deforming function is taking around 7% of the time here. Today, I was experimenting with the heuristic that selects the deformer. For now, I've made it so it checks the maximum attribute needed, and if we need more than half of the attributes before that one, then deform everything up to the max. Otherwise, only deform the required attributes. I also added a GUC to override the heuristic of which deformer is selected; debug_tuple_deform supports "incremental", "selective", and "auto". "incremental" is what I named the existing method. The GUC is only for testing. I don't anticipate keeping it. I tried all 3 of those GUC settings on the 41 column table and effectively did: SELECT col41 FROM t WHERE col41=0; and then progressively added the columns one by one in descending order. The "auto" setting will switch methods when there are 20 columns in the select list. See graph1.png for the performance results. This shows that when only a few columns are needed, the query time improves. With 1 column selected, patched 128% faster than master. Looking at the red line, you can see that as more columns are selected, the increase is less and less, and when all 41 columns are needed, selective deforming causes a performance regression. The black line shows the "auto" setting, which follows the red line (with noise) from 1-20, then the blue line from 21-41, from where the incremental method is used. graph2.png shows the performance of running the same queries as graph1, but the table has a varlena column as the first column. This means there's no use of cached offsets, and the tuple is always walked to find the offset for the first required column. This shows that the speedup for the 1 column case isn't as good, and the performance increase is just 99% faster than master. The gains still exist through not having to store Datums in tts_values that we don't need. The patch is tagged with "WIP", so not finished yet. There is no JIT support. I expect if you JIT any expression, bad things will happen. I've also only added support for Seq Scan. Other scan node types could be supported. The attached script can be run with "./select_deform_bench.sh setup" to create the table, then "./select_deform_bench.sh run" to run the test. Currently, varlena_first is set to 0. Set that to 1 to have a text column added as the first column. I'll happily take comments and further ideas here, but I won't be working on it with much priority until June. WIP patch is attached. David [1] https://postgr.es/m/CAApHDvpdB1t7LCgH8=KOKC6VBb2rsEbaas0FiXo5awsRgCsDxQ@mail.gmail.com
Attachment
{kind=link}
{kind=link}
pgsql-hackers by date: