Re: Trouble with hashagg spill I/O pattern and costing - Mailing list pgsql-hackers
| From | Tomas Vondra |
|---|---|
| Subject | Re: Trouble with hashagg spill I/O pattern and costing |
| Date | |
| Msg-id | 20200526141524.ohtvrp23vxosgivl@development Whole thread |
| In response to | Re: Trouble with hashagg spill I/O pattern and costing (Thomas Munro <thomas.munro@gmail.com>) |
| Responses |
Re: Trouble with hashagg spill I/O pattern and costing
|
| List | pgsql-hackers |
On Tue, May 26, 2020 at 05:02:41PM +1200, Thomas Munro wrote:
>On Tue, May 26, 2020 at 10:59 AM Tomas Vondra
><tomas.vondra@2ndquadrant.com> wrote:
>> On Mon, May 25, 2020 at 12:49:45PM -0700, Jeff Davis wrote:
>> >Do you think the difference in IO patterns is due to a difference in
>> >handling reads vs. writes in the kernel? Or do you think that 128
>> >blocks is not enough to amortize the cost of a seek for that device?
>>
>> I don't know. I kinda imagined it was due to the workers interfering
>> with each other, but that should affect the sort the same way, right?
>> I don't have any data to support this, at the moment - I can repeat
>> the iosnoop tests and analyze the data, of course.
>
>About the reads vs writes question: I know that reading and writing
>two interleaved sequential "streams" through the same fd confuses the
>read-ahead/write-behind heuristics on FreeBSD UFS (I mean: w(1),
>r(42), w(2), r(43), w(3), r(44), ...) so the performance is terrible
>on spinning media. Andrew Gierth reported that as a problem for
>sequential scans that are also writing back hint bits, and vacuum.
>However, in a quick test on a Linux 4.19 XFS system, using a program
>to generate interleaving read and write streams 1MB apart, I could see
>that it was still happily generating larger clustered I/Os. I have no
>clue for other operating systems. That said, even on Linux, reads and
>writes still have to compete for scant IOPS on slow-seek media (albeit
>hopefully in larger clustered I/Os)...
>
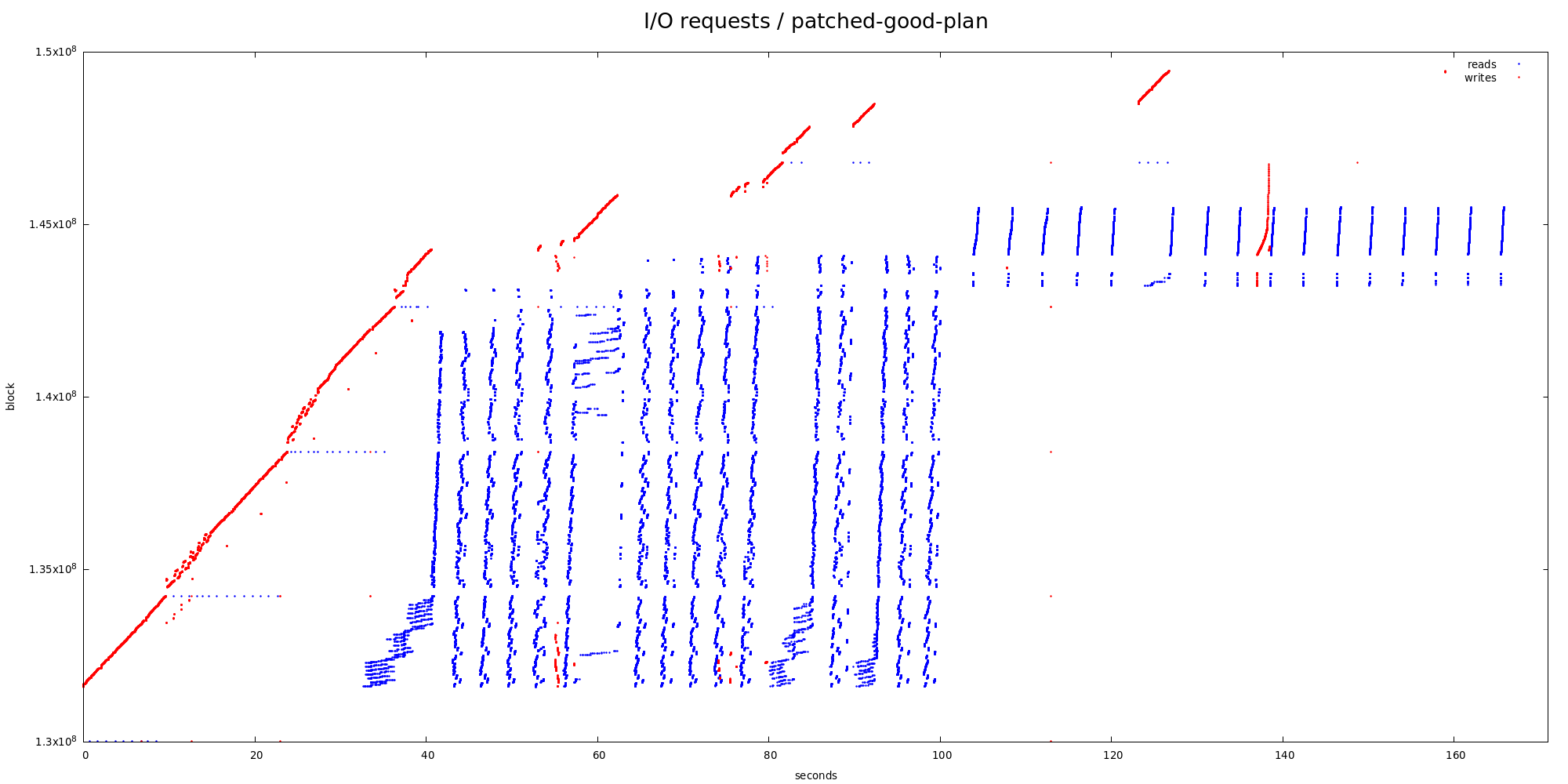
True. I've repeated the tests with collection of iosnoop stats, both for
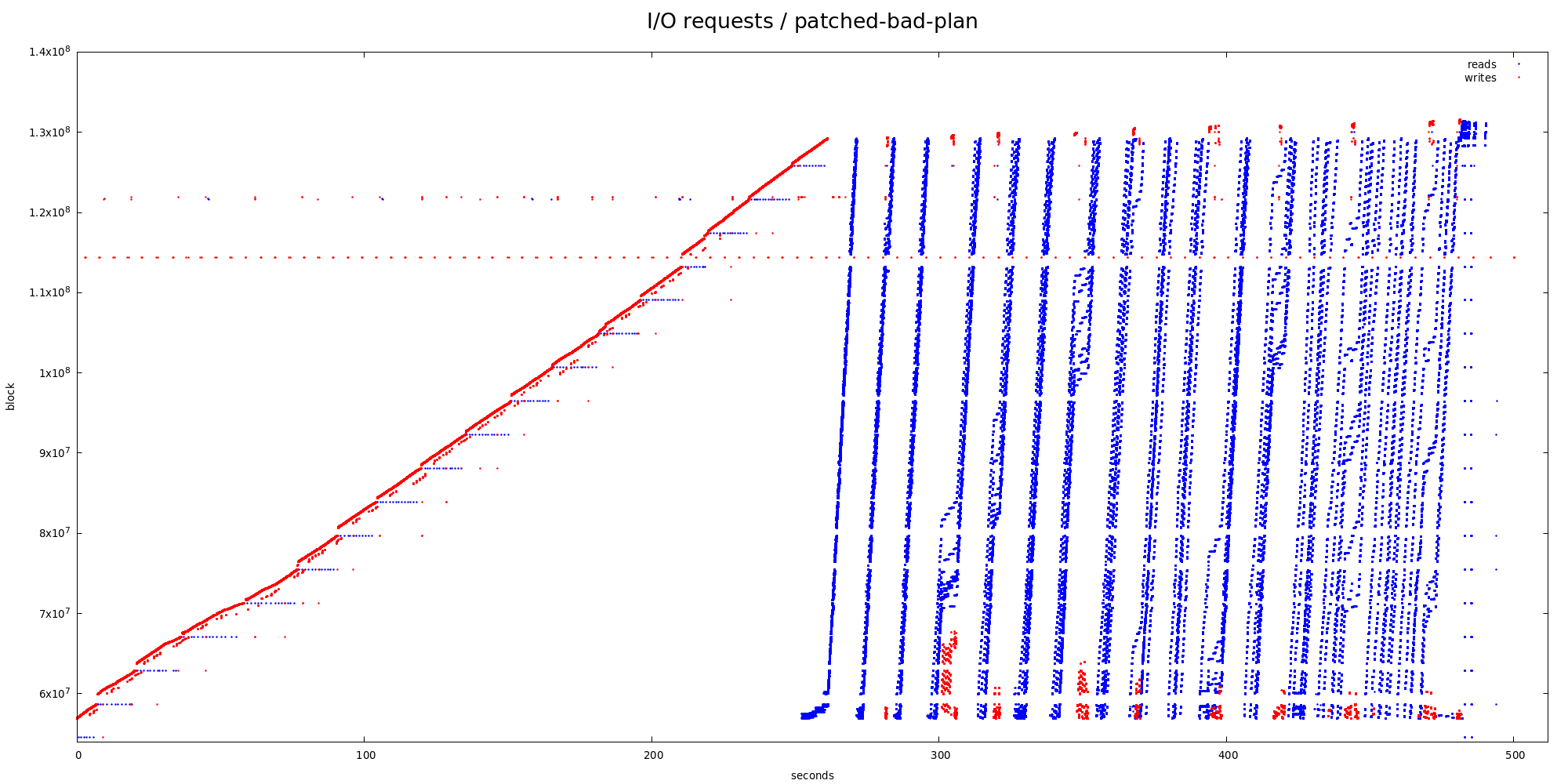
the good (partitioned hashagg) and bad (complete hashagg in each worker)
plans. Ignoring the fact that the bad plan does much more I/O in general
(about 32GB write + 35GB reads vs. 5.4GB + 7.6GB), request size stats
are almost exactly the same:
1) good plan (partitioned hashagg, ~180 seconds)
type | bytes | count | pct
------+---------+-------+-------
RA | 131072 | 39392 | 71.62
RA | 8192 | 5666 | 10.30
RA | 16384 | 3080 | 5.60
RA | 32768 | 2888 | 5.25
RA | 65536 | 2870 | 5.22
RA | 262144 | 710 | 1.29
W | 1310720 | 3138 | 32.01
W | 360448 | 633 | 6.46
W | 688128 | 538 | 5.49
W | 692224 | 301 | 3.07
W | 364544 | 247 | 2.52
W | 696320 | 182 | 1.86
W | 8192 | 164 | 1.67
W | 700416 | 116 | 1.18
W | 368640 | 102 | 1.04
2) bad plan (complete hashagg, ~500 seconds)
type | bytes | count | pct
------+---------+--------+--------
RA | 131072 | 258924 | 68.54
RA | 8192 | 31357 | 8.30
RA | 16384 | 27596 | 7.31
RA | 32768 | 26434 | 7.00
RA | 65536 | 26415 | 6.99
RM | 4096 | 532 | 100.00
W | 1310720 | 15346 | 34.64
W | 8192 | 911 | 2.06
W | 360448 | 816 | 1.84
W | 16384 | 726 | 1.64
W | 688128 | 545 | 1.23
W | 32768 | 544 | 1.23
W | 40960 | 486 | 1.10
W | 524288 | 457 | 1.03
So in both cases, majority of read requests (~70%) are 128kB, with
additional ~25% happening in request larger than 8kB. In terms of I/O,
that's more than 90% of read I/O.
There is some difference in the "I/O delta" stats, showing how far the
queued I/O requests are. The write stats look almost exactly the same,
but for reads it looks like this:
1) good plan
type | block_delta | count | pct
------+-------------+-------+-------
RA | 256 | 7555 | 13.74
RA | 64 | 2297 | 4.18
RA | 32 | 685 | 1.25
RA | 128 | 613 | 1.11
RA | 16 | 612 | 1.11
2) bad plans
type | block_delta | count | pct
------+-------------+-------+-------
RA | 64 | 18817 | 4.98
RA | 30480 | 9778 | 2.59
RA | 256 | 9437 | 2.50
Ideally this should match the block size stats (it's in sectors, so 256
is 128kB). Unfortunately this does not work all that great - even for
the "good" plan it's only about 14% vs. 70% (of 128kB blocks). In the
serial plan (disabled parallelism) this was ~70% vs. 75%, much closer.
Anyway, I think this shows that the read-ahead works pretty well even
with multiple workers - otherwise there wouldn't be that many 128kB
requests. The poor correlation with 128kB deltas is unfortunate, but I
don't think we can really fix that.
This was on linux (5.6.0) with ext4, but I don't think the filesystem
matters that much - the read-ahead happens in page cache I think.
>Jumping over large interleaving chunks with no prefetching from other
>tapes *must* produce stalls though... and if you crank up the read
>ahead size to be a decent percentage of the contiguous chunk size, I
>guess you must also waste I/O bandwidth on unwanted data past the end
>of each chunk, no?
>
>In an off-list chat with Jeff about whether Hash Join should use
>logtape.c for its partitions too, the first thought I had was that to
>be competitive with separate files, perhaps you'd need to write out a
>list of block ranges for each tape (rather than just next pointers on
>each block), so that you have the visibility required to control
>prefetching explicitly. I guess that would be a bit like the list of
>physical extents that Linux commands like filefrag(8) and xfs_bmap(8)
>can show you for regular files. (Other thoughts included worrying
>about how to make it allocate and stream blocks in parallel queries,
>...!?#$)
I was wondering how useful would it be to do explicit prefetch too.
I'm not familiar with logtape internals but IIRC the blocks are linked
by each block having a pointer to the prev/next block, which means we
can't prefetch more than one block ahead I think. But maybe I'm wrong,
or maybe fetching even just one block ahead would help ...
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
{kind=link}
{kind=link}
pgsql-hackers by date: