New TOAST in town: the “pluggable TOAST API” concept and what it means for the community

While preparing for my talk to be given at PGCon 2022, I decided to share some important thoughts with the Postgres community. We’re going to change the way TOAST works, and it will have a positive impact on lives of many PostgreSQL contributors, developers and users in the upcoming years. It is also the rare case when I tackle commercial aspects of open source development, so it’s worth reading for everyone.
Last year Nikita Glukhov and me were working on JSONB performance improvements. As many of you know, we have found a number of possible optimizations enabling JSONB SELECT and UPDATE speed-up by several orders of magnitude. Our optimizations were mostly intended for long JSONB documents as modern application developers often create very simple database schemas like: CREATE TABLE (id int, data jsonb). Our guess was 100% right: a type-aware TOAST could work significantly better taking the properties of the given data type into account.
We have also experimented with performance of appendable bytea. When we optimized TOAST for append-only mode, it became possible to literally stream to PostgreSQL tables! So adjusting TOAST to certain workload also resulted in several orders of magnitude better performance.
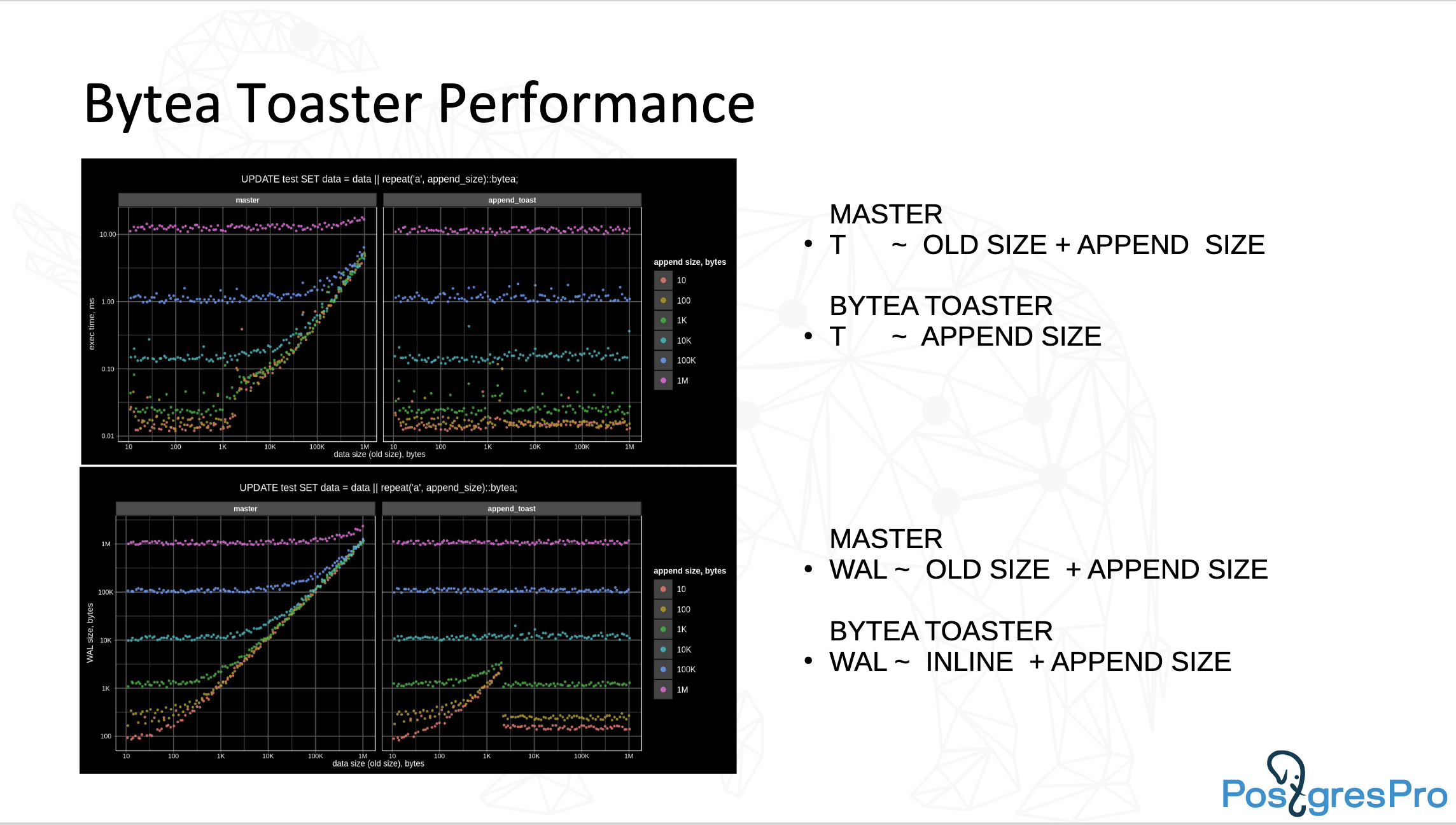
Upper graphs demonstrate bytea toaster vs. vanilla TOAST performance;
lower graphs display the decrease in WAL size.
For more info on these optimizations, see my PGConf.Online talk.
The value of our approach was obvious, but it wasn’t clear when the Postgres community would be able to benefit from our experiments. It took 5 years to get the SQL/JSON series of patches committed to the core, and it’s a long time in today’s IT world. What could be done to optimize the adoption of our optimizations? Should we create a replacement for TOAST?
Let’s get back to what TOAST is and does. TOAST remains a reliable technology; it worked perfectly well when it was invented. However, with the rise of JSON(b) and other modern data types, it needs to be modernized, too. For now, it includes only four built-in strategies (passes) for work with attributes (columns), and that’s all it has to offer to accommodate various data types and workloads. (See slides 18-24 in my last year’s JSONB presentation for TOAST passes explained.) These strategies are quite primitive, and you cannot change them. So time has come for a new kid in town!
Thinking the Postgres way, we finally decided to further extend PostgreSQL extensibility and create TOAST API for everyone to be able to add their custom toasters as extensions. Basically, we came up with an idea of “pluggable” TOAST that is smart and type-aware thanks to toasters. Unlike the “vanilla” TOAST, a toaster is type-aware and can adjust to a specific data type or a workload type optimizing TOAST for this data type or workload respectively. So one TOAST still fits all!
Every system API creation assumes a lot of work, so I need to thank Teodor Sigaev and Nikita Malakhov who helped Nikita Glukhov and myself to create the TOAST API and three toasters: a default toaster for backward compatibility, a jsonb_toaster and a bytea_toaster.
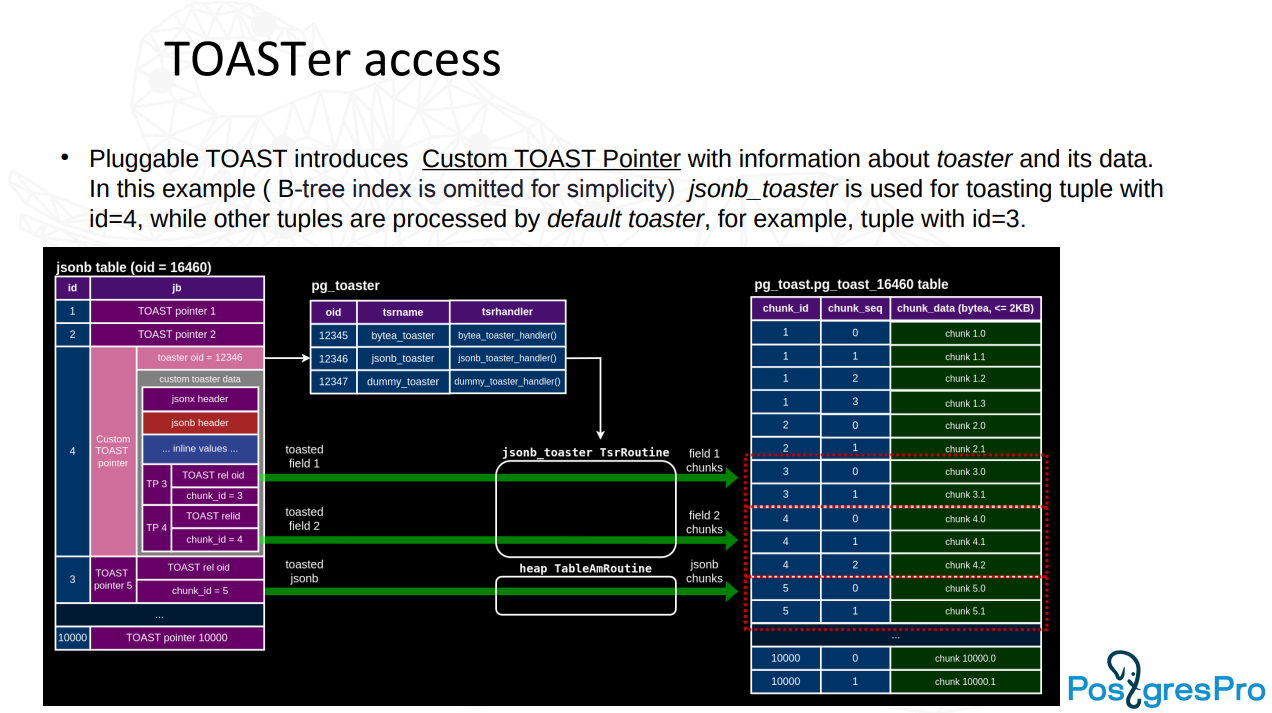
Simultaneous usage of jsonb_toaster and default toaster thanks to custom TOAST pointer.
A lot of work is still to be done, however, we can share the initial results and discuss the entire concept with the community in detail. Our goal is to have the TOAST API committed to PostgreSQL 16, and we are open to good ideas and reviews.
This new pluggable TOAST API could help Postgres developers get what they need very fast by creating a new extension. They will not depend on the PostgreSQL release cycle or have to wait until their patch is reviewed and approved by the community, they can create a toaster for themselves to use and move on.
Moreover, these extensions can be published under custom licenses which is important. Someone may want to make money on writing Postgres toasters, and this is a simple way for open source allies to get stable income. Another crucial thing is that a custom license will enable toaster authors to limit their code usage.
Why do we as open source community members want to set those limits? Some OSS market players like Elasticsearch, MariaDB, MongoDB have recently introduced SSPL or similar licenses to prevent cloud providers from uncontrolled usage of their open source products without giving anything back to the corresponding communities. Our toaster authors may want to take advantage of this model, too.
Setting limits for usage of certain functionality not coming with Postgres could make these cloud vendors change their attitude to open source communities and particularly Postgres. I’ve been a member of PostgreSQL community since 1995 and know how much effort it took us all to make Postgres a first-choice database for many world-famous businesses. I remember how many people were involved with this success and understand that just using the outcomes is not a fair play. Giving back is key.
We at Postgres Professional do monetize our commercial fork of PostgreSQL, the Postgres Pro DBMS. However, we continue to contribute to the community, and many of our patches get committed to the core (see PostgreSQL git log and Release Notes). Many features that are now a part of PostgreSQL core were first developed for Postgres Pro DBMS where they got tested and polished. Whenever we have capacity, we take part in the important processes around PostgreSQL, and we do a lot of work related to education, advocacy, documentation, bug fixing, etc. This is the duty of every vendor company, and we understand it. Hopefully, cloud vendors will understand it too, if more valuable extensions will become unavailable for them.
To get more information about the “pluggable TOAST API” concept, you can read our PGCon abstract below and actually attend our PGCon session online this Friday, May 27 at 12:15 EDT. I’ll be explaining the idea and demonstrate some benchmark test results, and Nikita Malakhov will walk you through the internals of the TOAST API and our first toasters.
New TOAST in Town. One TOAST FITS ALL.
Postgres handles long attributes in a table by compressing and slicing them to chunks stored in a hidden corresponding relation; this technology is called TOAST. Any access to such attribute requires lookup through chunks using a Btree index and further implicit joining to the hidden relation, which can cause a catastrophic slowdown of all queries to such attributes. Nowadays, users prefer to use JSON because of its flexible nature and ubiquity; they often operate with long JSON documents and face performance issues. Unfortunately, the current TOAST is too universal in regards to the types of data, it knows nothing about the internal structure of an attribute considering it as a black box. We propose a new pluggable TOAST API, which allows per data type optimizations of storage for long attributes. I will also show several examples of how to use the new TOAST and explain which benefits it brings, including streaming to table using appendable bytea and very efficient JSONB, which demonstrates orders of magnitude performance gain on selects and updates.
PGCon 2022 Schedule (still subject to change):
https://www.pgcon.org/events/pgcon_2022/schedule/
Related links:
http://www.sai.msu.su/~megera/postgres/talks/jsonb-pg..
http://www.sai.msu.su/~megera/postgres/talks/jsonb-pg..
http://www.sai.msu.su/~megera/postgres/talks/bytea-pg..
https://commitfest.postgresql.org/38/3490/

Oleg Bartunov
President of Postgres Professional
A major contributor to PostgreSQL, Bartunov has been using PostgreSQL since 1995 and has been developing and promoting PostgreSQL since 1996. His PostgreSQL contributions include the locale support, GiST, GIN, and SP-GiST extensibility infrastructures, full text search, KNN, NoSQL features (HStore and JSONB), and several extensions including fuzzy search, support for tree-like structures, and arrays.
Currently, he is working on extending TOAST capabilities and performance optimizations for JSONB data type.