SQL/JSON patches committed to PostgreSQL 15!

As PostgreSQL 15 moves to the feature freeze stage, we’d like to share the news about our team’s JSONB-related patches committed to version 15. This milestone marks years of work for many people, so we will name and thank them all in this blog post.
Most of these innovations aimed at compatibility with the SQL:2016 standard were introduced by Postgres Professional a long time ago. However, the community needed a while to review and approve these large patches.
Introduction to SQL/JSON
The success of JSON[B] in PostgreSQL resulted in JSON support becoming a standard feature in all major databases. Later, JSON became the main feature described in the SQL:2016 standard.

The SQL:2016 standard didn't describe JSON as a data type like XML. Instead, it introduced the SQL/JSON data model with a string storage and a path language used by certain SQL/JSON functions to query JSON. The SQL/JSON data model is a sequence of items. Each item consists of SQL scalar values with an additional SQL/JSON null value and composite data structures using JSON arrays and objects.
PostgreSQL has two JSON data types: JSON and JSONB. A textual JSON data type serves to store an exact copy of the input text. JSONB is binary storage for JSON data converted to PostgreSQL types, according to mapping in JSON primitive types and the corresponding PostgreSQL types. The SQL/JSON data model adds a datetime type to these primitive types, but it is only used for comparison operators in path expression and stored on a disk as a string. Thus, JSONB data conforms to SQL/JSON data model (ORDERED and UNIQUE KEYS), while JSON should be converted according to the mapping. The SQL:2016 standard describes two sets of SQL/JSON functions: constructor functions and query functions. Constructor functions use values of SQL types and produce JSON values (JSON objects or JSON arrays) represented in SQL characters or binary string types. Query functions evaluate SQL/JSON path language expressions against JSON values, producing values of SQL/JSON types, which are then converted to SQL types.
Newest JSON[B]-related features in PostgreSQL 15
IS JSON predicate helps validate documents in the JSON format. Having such a predicate in place is required by the SQL:2016 standard.
SQL/JSON standard constructors for JSON are a set of functions including JSON(), JSON_ARRAY(), JSON_ARRAYAGG(), JSON_OBJECT()and JSON_OBJECTAGG().They provide facilities that mimic existing JSON/JSONB functions and some useful additional functionality for accepting BYTEA input and handling duplicate keys and null values.
JSON_TABLE function helps obtain a relational view of data coming in the JSON format and further process this data as a relational table.
SQL/JSON query functions are intended for querying JSON data using JSONPATH expressions. All of these functions (JSON_EXISTS(), JSON_QUERY(), JSON_VALUE()) only operate on JSONB.
Credits for contributions
Nikita Glukhov, a PostgreSQL contributor who worked at Postgres Professional, gets credits for the code of all these projects and “probably deserves an award for perseverance” as these patches had been under review since 2018.
Andrew Dunstan, a PostgreSQL Major Contributor, took responsibility for committing the above-mentioned patches to PostgreSQL 15. We have known each other since the early years of Postgres, and Andrew has always strived to keep up the good work.
The reviewers list includes Andres Freund, Alexander Korotkov, Pavel Stehule, Andrew Alsup, Erik Rijkers, Zihong Yu, Himanshu Upadhyaya, Daniel Gustafsson, and Justin Pryzby. We thank them all for the fantastic job of making Nikita’s innovations meet PostgreSQL’s high code standards.
Liudmila Mantrova, Postgres Professional’s technical writer, who wrote documentation for SQL/JSON, also gets our special thanks.
Having started this project in 2017, I dedicated many hours to its management, SQL/JSON patches testing, benchmarking, and conference appearances. Understanding the standard had not been an easy task, and it took a lot of our time. We also needed to drive awareness of the future benefits for the community, attract reviewers, etc. I’m glad my contributions helped, too.
Taking a closer look at SQL/JSON innovations
When we add new functionality to a large open source project like PostgreSQL, it is essential to understand who and how will benefit from it. For those not subscribed to the PostgreSQL hackers mailing list, I need to explain what these new features will bring to us as Postgres users.
JSON_TABLE is definitely a feature long-awaited by the PostgreSQL community. It queries the JSON text and presents the results as a relational table, which can be used later as a regular table, i.e., for join operations or aggregation.
Example 1. We have a JSON document containing the description of a two-floor house and need to understand which apartments are available there.
Step 1. Let’s have a look at the document.
CREATE TABLE house(js) AS SELECT jsonb ' -- two-floor house
{
"lift": false,
"floor" : [
{
"level": 1,
"apt": [
{"no": 1, "area": 40, "rooms": 1},
{"no": 2, "area": 80, "rooms": 3},
{"no": 3, "area": null, "rooms": 2}
]
},
{
"level": 2,
"apt": [
{"no": 4, "area": 100, "rooms": 3},|
{"no": 5, "area": 60, "rooms": 2}
]
}
]
}';Step 2. Let’s pull a list of apartments in a relational view using the JSON_TABLE retrieval function.
SELECT
jt.*
FROM
house,
JSON_TABLE(js, '$.floor[*]' COLUMNS (
level int,
NESTED PATH '$.apt[*]' COLUMNS (
no int,
area float,
rooms int
)
)) jt;level | no | area | rooms
-------+----+--------+-------
1 | 1 | 40 | 1
1 | 2 | 80 | 3
1 | 3 | (null) | 2
2 | 4 | 100 | 3
2 | 5 | 60 | 2
(5 rows)
Step 3. What if we need to specify the floor for each apartment in a human-readable form? Let’s join our JSON data with the levels table using the JSON_TABLE function.
CREATE TABLE levels ( level, name ) AS VALUES (1,'first floor'),(2,'second floor');|
SELECT
levels.name, jt.*
FROM
house,
JSON_TABLE(js, '$.floor[*]' COLUMNS (
level int,
NESTED PATH '$.apt[*]' COLUMNS (
no int,
area float,
rooms int
)
)) jt, levels
WHERE jt.level = levels.level;name | level | no | area | rooms
--------------+-------+----+--------+-------
second floor | 2 | 5 | 60 | 2
second floor | 2 | 4 | 100 | 3
first floor | 1 | 3 | (null) | 2
first floor | 1 | 2 | 80 | 3
first floor | 1 | 1 | 40 | 1
(5 rows)
So we can see on which floor each apartment is located, which number, which area, and how many rooms it has.
SQL/JSON ensures compliance with SQL:2016 standard and interoperability with other database management systems relying on this standard.
Here I need to say that the PostgreSQL community has always been respectful of industry standards. At FOSDEM PGDay 2017, I learned about SQL:2016, which was released a few months ago in 2016, so I bought a copy of the standard for myself. Then I spent several days reading it and decided to ensure compliance for JSON in Postgres. JSON was a part of the standard; we worked on JSON-related projects, so it was a logical and timely contribution to the community.
Standards simplify developers’ lives, and SQL/JSON will help them write code that works equally well with various databases. Database-to-database migrations will also become less painful for the users.
When I say “simplify”, I really mean it. Construction functions in SQL/JSON bring new opportunities for easy object and array construction and aggregation:

Advanced retrieval functions are the other side of the medal. We will be able to pull a lot of information from a JSON document using the standard SQL/JSON functions committed to Postgres 15:

Many of our SQL/JSON features that became a part of PostgreSQL 15 rely on JSONPath. It is a set of functionalities to address data inside JSON, available to Postgres users since version 12. The newly committed SQL/JSON functions will work smoothly with JSONPath, as these features were developed at the same time in 2018 and are “aware” of each other.
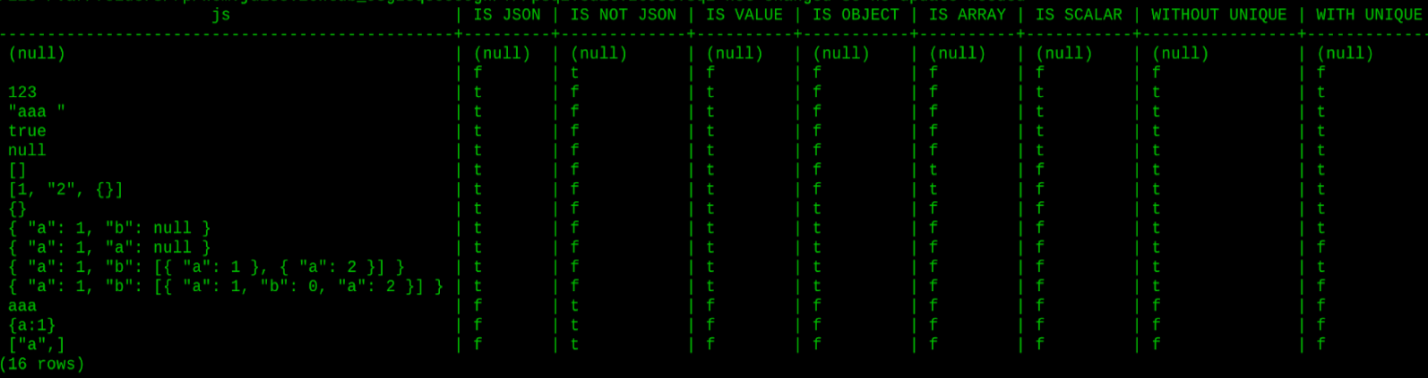
IS JSON predicate serves to validate JSON documents per the SQL:2016 standard. IS JSON will help detect errors inside JSON, and find suspicious contents and empty documents.
Example 2. IS JSON validation mechanism
SELECT js,
js IS JSON "IS JSON",
js IS NOT JSON "IS NOT JSON",
js IS JSON VALUE "IS VALUE",
js IS JSON OBJECT "IS OBJECT",
js IS JSON ARRAY "IS ARRAY",
js IS JSON SCALAR "IS SCALAR",
js IS JSON WITHOUT UNIQUE KEYS "WITHOUT UNIQUE",
js IS JSON WITH UNIQUE KEYS "WITH UNIQUE"
FROM
( VALUES
(NULL),
(''),
('123'),
('"aaa "'),
('true'),
('null'),
('[]'),
('[1, "2", {}]'),
('{}'),
('{ "a": 1, "b": null }'),
('{ "a": 1, "a": null }'),
('{ "a": 1, "b": [{ "a": 1 }, { "a": 2 }] }'),
('{ "a": 1, "b": [{ "a": 1, "b": 0, "a": 2 }] }'),
('aaa'),
('{a:1}'),
('["a",]')
) AS t (js);
Example 3. How to implement constraints using IS JSON?
CREATE TABLE test_json_constraints (
js text,
i int,
x jsonb DEFAULT JSON_QUERY(jsonb '[1,2]', '$[*]' WITH WRAPPER)
CONSTRAINT test_json_constraint1
CHECK (js IS JSON)
CONSTRAINT test_json_constraint2
CHECK (JSON_EXISTS(js::jsonb, '$.a' PASSING i + 5 AS int, i::text AS txt))
CONSTRAINT test_json_constraint3
CHECK (JSON_VALUE(js::jsonb, '$.a' RETURNING int DEFAULT ('12' || i)::int
ON EMPTY ERROR ON ERROR) > i)
CONSTRAINT test_json_constraint4
CHECK (JSON_QUERY(js::jsonb, '$.a'
WITH CONDITIONAL WRAPPER EMPTY OBJECT ON ERROR) < jsonb '[10]')
);
INSERT INTO test_json_constraints VALUES ( '{"a":"aaa"}', 1);
ERROR: invalid input syntax for type integer: "aaa"
INSERT INTO test_json_constraints VALUES ( '{"a":2}', 1);
INSERT 0 1
SELECT * FROM test_json_constraints;
js | i | x
---------+---+--------
{"a":2} | 1 | [1, 2]
(1 row)
This validation mechanism will also help implement larger community projects, for example, JSON Schema.
What is JSON Schema? It is a project that establishes cross-database rules to validate and describe JSON documents in both SQL and NoSQL databases. The project is still being developed, but several database companies are ready to support it. Standard descriptions will be applied to data types, fields, keys, values, arrays, etc. With JSON Schema in place, it will be possible to implement JSON dictionary compression. In this case, long keys described in the JSON Schema could be replaced by their short IDs.
NoSQL in PostgreSQL: the story behind
Next year will mark the 20th anniversary of the first developments related to the support of semi-structured data in Postgres. We have been creating NoSQL features for Postgres since 2003, transforming it into a “one-fits-all” solution for many real-world use cases.
In 2003, Teodor Sigaev and I invented the HSTORE data type for storing arbitrary key-value pairs, which allowed schemaless in PostgreSQL in those early days. It was committed to Postgres in 2006. Later, HSTORE improvements enabled us to create JSONB. My earliest posts covering JSONB are available in my LiveJournal account. Below you can see a brief story of how NoSQL Postgres evolved:

This is a slide from my presentation given at PGConf US 2017 that took place in Jersey City on March 28-31, 2017. So it’s been five years since SQL/JSON was first mentioned in public.
As you can see, initially, we sent the SQL/JSON set of patches for review in 2018. However, submitting a large patch pre-assumes long back and forth discussions and considerable time for community reviews. The procedure is lengthy, but this is how we provide the quality of code PostgreSQL is famous for. The following slide illustrates this quite well:

So it took us five years to get SQL/JSON and JSON_TABLE committed, with 65 versions and 59 versions reviewed, respectively. The entire Postgres team deserves praise for pushing this project forward. Great job!
The patches have now been committed to the main branch and will become available this fall as part of the PostgreSQL 15 release.
The future of semi-structured data in PostgreSQL
We will continue to work on various JSONB-related improvements in the next few years.
There's a need to improve the compression of JSON documents in PostgreSQL as JSON Schema becomes a reality (and we agreed to get involved in this project to help the team make progress faster). We experimented with automatic dictionary-based compression, but we faced problems such as bloating dictionaries, concurrent updates, etc. On the contrary, JSON Schema looks better since the keys become known with schema definition.
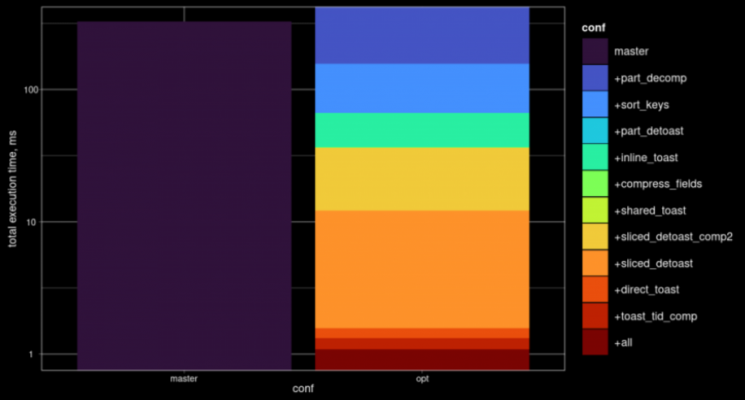
Also, we’ll see what can be done to speed up JSON processing in Postgres. In my presentation at PGConf NYC 2021, I mentioned a problem related to how TOAST usually operates. TOAST was originally designed for atomic data types; it knows nothing about the internal structure of composite data types like JSONB, HSTORE, or even ordinary arrays. If JSON is slightly updated, we get extra-large overheads. We experimented to prove that a type-aware TOAST could ensure better performance, and the result was positive. Based on our successful experiments, we introduced a pluggable TOAST patch currently being reviewed by the community.
The picture below presents the results of different optimizations implemented in the JSONB toaster for pluggable TOAST, with particular mechanisms listed to the right. If we apply all of them (+all), performance improves by two orders of magnitude.
SQL:2016 is not the most current version of the standard. So we need to think of SQL:2019 which explicitly describes SQL JSON as a data type, not a model. This means we need to have just one JSON data type in Postgres for compliance. As I have already explained earlier, PostgreSQL now has two JSON data types, JSON (a textual type) and JSONB (a binary type). Each of them is good for specific use cases or projects, so we need to ensure compliance while preserving flexibility for the users. They should be able to choose whether they need a ‘slow’ textual JSON or a ‘fast’ binary JSONB. So we need to find a solution to accommodate the users and still comply with SQL:2019. Postgres Professional team has already developed a Generic JSON (GSON) API that unifies access to JSON and JSONB. GSON API also allows us to develop an easy way for the user to choose which 'JSON' to use. These solutions were first introduced at Postgres Build 2020, where I was giving a talk on the JSONB roadmap. It looks like an elegant way out with little change for PostgreSQL (and JSONB!) users, but it will require some coding work from us as Postgres developers.
Example 4. Setting the JSON data type to JSONB to use GIN indexing for JSON.
SET sql_json = jsonb;
CREATE TABLE js (js json);
CREATE INDEX ON js USING GIN (js jsonb_path_ops);
Another goal is to improve JSONB indexing. Parameters for opclasses have already been committed to PostgreSQL. However, we still need to work on projective indexing for JSONB indexes to reduce index size and building time. Projective indexing allows users to index only parts of a JSON tree stored as JSONB columns using JSONPATH expression, which means that only the necessary keys are indexed. Our team has added opclass options to GIN jsonb_ops and jsonb_path_ops and implemented this feature as a prototype, but it requires refactoring and additional testing. We introduced parameters for opclasses and projective indexing at PGCon 2018 in Ottawa.
Example 5. Creating a projective index.
CREATE INDEX bookmarks_selective_path_idx ON bookmarks
USING gin(js jsonb_path_ops(projection='strict $.tags[*].term'));
Of course, these are not the only tasks to be completed in the next few years. I have mentioned a few others in my presentation at Postgres Build 2020 (see slides 98-109): a variety JSONPath syntax extensions, simple dot-notation access to JSON data, the implementation of COPY ... (FORMAT json).
Conclusions
It is great to see a SQL database supporting the SQL standard, even in the document store functionality. SQL/JSON is no doubt a significant milestone. The next stop is SQL:2019 compliance.
NoSQL features in PostgreSQL are developing and in high demand. There grounds for it: many modern software developers prefer to work with documents and are not necessarily good at the theory of relational databases. So document store functionality will thrive in the SQL world, too. Last year’s survey "State of PostgreSQL 2021" clearly demonstrated the importance of JSON[B]:

Moreover, I also believe that JSONB availability explains PostgreSQL's growing popularity since 2014:
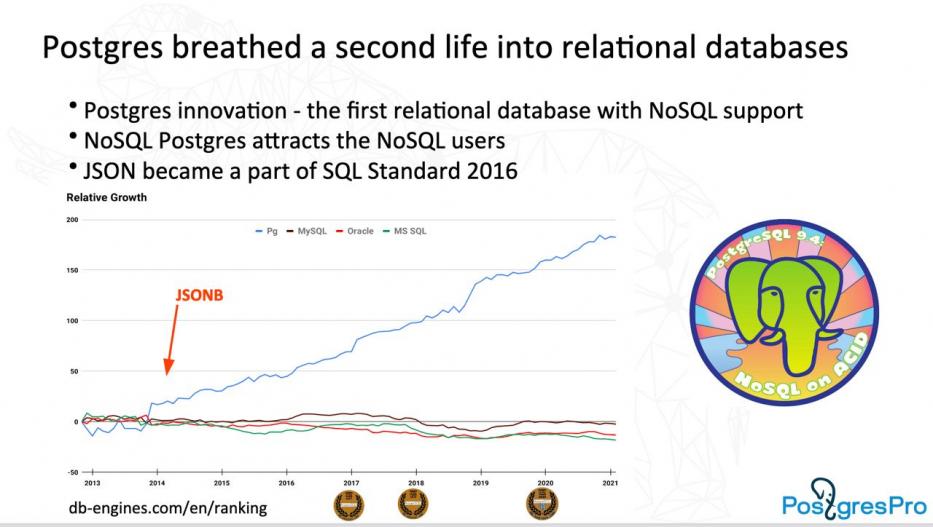
Postgres needs to accommodate NoSQL users to remain a present-day technology. So far, it has succeeded. JSONB made it an universal DBMS, and the coming enhancements will continue to transform Postgres into a multi-purpose solution. We would be glad to see our employees, interns and students investing more effort into NoSQL in PostgreSQL. Everyone's contribution is welcome, it's all about future and progress.
We at Postgres Professional see the PostgreSQL community working hard over the years to make Postgres better for all. Many valuable contributions to PostgreSQL like pluggable TOAST and 64-bit transactions addressing the wraparound problem in Postgres are still awaiting reviews. If you have enough bandwidth, you can participate in discussions, the community will appreciate your thoughts and commentaries.

Oleg Bartunov
President of Postgres Professional
A major contributor to PostgreSQL, Bartunov has been using PostgreSQL since 1995 and has been developing and promoting PostgreSQL since 1996. His PostgreSQL contributions include the locale support, GiST, GIN, and SP-GiST extensibility infrastructures, full text search, KNN, NoSQL features (HStore and JSONB), and several extensions including fuzzy search, support for tree-like structures, and arrays.
Currently, he is working on extending TOAST capabilities and performance optimizations for JSONB data type.