Scaling PostgreSQL at multicore Power8
Recently, we got access to a big server: IBM 9119-MHE with 8 CPUs * 8 cores * 8 threads. We decided to take advantage of this and investigate the read scalability of postgres (pgbench -S) at this server.
 Dmitry Vasilyev is benchmarking IBM P8 server.
Dmitry Vasilyev is benchmarking IBM P8 server.
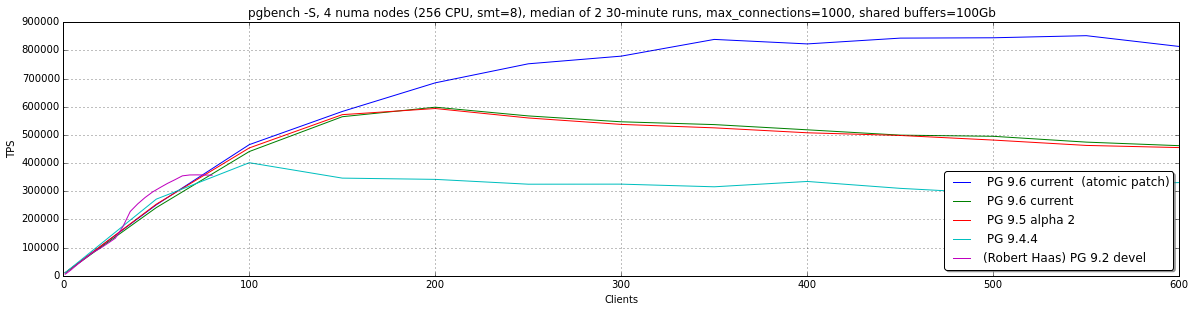
Performance of 9.4 stops growing after 100 clients, and 9.5 / 9.6 stop after 150 (at 4 NUMA nodes). Then we tried to identify bottlenecks using perf. We have seen the following picture in perf top:
32.10% postgres [.] s_lock 7.77% postgres [.] GetSnapshotData 2.64% postgres [.] AllocSetAlloc 1.40% postgres [.] hash_search_with_hash_value 1.37% postgres [.] base_yyparse 1.36% postgres [.] SearchCatCache 1.32% postgres [.] PinBuffer 1.23% postgres [.] LWLockAcquire 1.05% postgres [.] palloc 1.01% postgres [.] ReadBuffer_common 0.99% postgres [.] LWLockRelease 0.94% libc-2.17.so [.] __memset_power7
More than 32% of time was taken by s_lock. Random probes using gdb had shown us that PinBuffer and UnpinBuffer were responsible for high contention on s_lock. These functions are used to increment and decrement a reference counter and implemented using buf_hdr_lock. We haven't yet carefully verified all the logic of the buffer manager. However, it should be possible to completely get rid of buf_hdr_lock by using atomic operation everywhere.
For testing purposes, we made a simplistic patch to implement PinBuffer and UnpinBuffer using atomic operations instead of buf_hdr_lock. After that, the degradation of performance almost completely disappeared and it continued to scale up to 400 clients (4 NUMA nodes with 256 logical CPUs).
The results are given in the following graph. We compared 9.4.4, 9.5, 9.6 and the patched 9.6. A significant difference between 9.4 and 9.5 can be seen. This can be explained by introduction of atomics operations and their usage in LWlocks. We didn’t notice any significant difference between 9.5 and 9.6dev.
We also put there data from the famous testing results of Robert Haas’s 9.2 scalability report. It would be better to rerun those tests, but we have no suitable server right now, so it can’t be considered as a direct comparison. However, it can be noticed that in our test case we have similar TPS per client and while Power8 has the same number of physical cores, its threads allow PostgreSQL to scale up.
With patched version we got following perf top picture. The slowest function now is GetSnapshotData, which is frequently mentioned in scalability issues.
13.75% postgres [.] GetSnapshotData 4.88% postgres [.] AllocSetAlloc 2.47% postgres [.] LWLockAcquire 2.11% postgres [.] hash_search_with_hash_value 2.02% postgres [.] SearchCatCache 2.00% postgres [.] palloc 1.81% postgres [.] base_yyparse 1.69% libc-2.17.so [.] __memset_power7 1.63% postgres [.] LWLockRelease 1.56% libc-2.17.so [.] __memcpy_power7 1.33% postgres [.] _bt_compare 0.99% postgres [.] core_yylex 0.99% postgres [.] expression_tree_walker
We are working on further investigations of performance on P8 and developing the complete patch to replace buf_hdr_lock by atomic operations. We would appreciate any help with testing our patch on other platforms, i.e., multicore x86.